Show HN: I built a zero-browser, pure-JS typesetting engine for bit-perfect PDFs
github.com66 points by cosmiciron 20 hours ago
66 points by cosmiciron 20 hours ago
Hi HN, I'm a film director by trade, and I prefer writing my stories in plain text rather than using clunky screenplay software. Standard markup like Fountain doesn't work for me because I write in mixed languages, so I use Markdown with a custom syntax I invented to resemble standard screenplay structures.
This workflow is great until I need to actually generate an industry-standard screenplay PDF. I got tired of manually copying and pasting my text back into the clunky software just to export it, so I decided to write a script to automate the process. That's when I hit a wall.
I tried using React-pdf and other high-level libraries, but they failed me on two fronts: true multilingual text shaping, and complex contextual pagination. Specifically, the strict screenplay requirement to automatically inject (MORE) at the bottom of a page and (CONT'D) at the top of the next page when a character's dialogue is split across a page break.
You can't really do that elegantly when the layout engine is a black box. So, I bypassed them and built my own typesetting engine from scratch.
VMPrint is a deterministic, zero-browser layout VM written in pure TypeScript. It abandons the DOM entirely. It loads OpenType fonts, runs grapheme-accurate text segmentation (Intl.Segmenter), calculates interval-arithmetic spatial boundaries for text wrapping, and outputs a flat array of absolute coordinates.
Some stats:
Zero dependencies on Node.js APIs or the DOM (runs in Cloudflare Workers, Lambda, browser).
88 KiB core packed.
Performance: On a Snapdragon Elite ARM chip, the engine's "God Fixture" (8 pages of mixed CJK, Arabic RTL, drop caps, and multi-page spanning tables) completes layout and rendering in ~28ms.
The repo also includes draft2final, the CLI tool I built to convert Markdown into publication-grade PDFs (including the screenplay flavor) using this engine.
This is my first open-source launch. The manuscript is still waiting, but the engine shipped instead. I’d love to hear your thoughts, answer any questions about the math or the architecture, and see if anyone else finds this useful!
--- A note on AI usage: To be fully transparent about how this was built, I engineered the core concept (an all-flat, morphable box-based system inspired by game engines, applied to page layouts), the interval-arithmetic math, the grapheme segmentation, and the layout logic entirely by hand. I did use AI as a coding assistant at the functional level, but the overall software architecture, component structures, and APIs were meticulously designed by me.
For a little background: I’ve been a professional systems engineer since 1992. I’ve worked as a senior system architect for several Fortune 500 companies and currently serve as Chief Scientist at a major telecom infrastructure provider. I also created one of the world's first real-time video encoding technologies for low-power mobile phones (in the pre-smartphone era). I'm no stranger to deep tech, and a deterministic layout VM is exactly the kind of strict, math-heavy system that simply cannot be effectively constructed with a few lines of AI prompts.
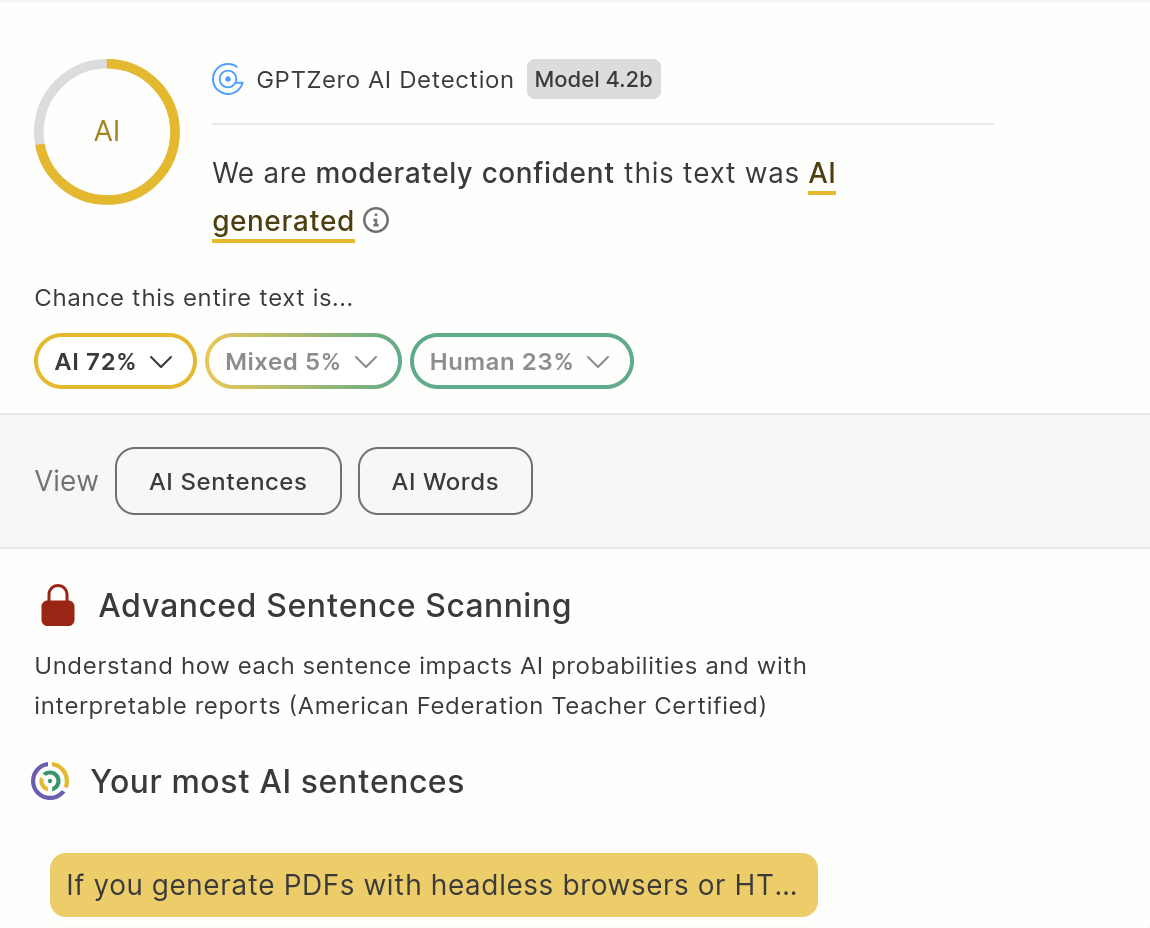
> If you generate PDFs with headless browsers or HTML-to-PDF tools, you've accepted a compromise: heavy dependencies, memory leaks, and "approximate" layout that shifts across environments Absolutely not true with Prince[0]. It's an HTML/CSS-based typesetter built by the creator of CSS (Håkon Wium Lie [1]) that is lightweight, cross-platform, requires no dependencies, has no memory leaks, is 100% consistent in its output, is fully compliant with the relevant standards, and has a lot of really great print-oriented features (like using CSS to control things like page headers/footers, numbering, etc.). Prince has been used to typeset a lot of different print output types, from posters to books to scientific papers. It's even a viable alternative to LaTex. I've used it in the past, and can attest that it is outstanding. Thanks for the correction. I'm actually not familiar with Prince, so I really can't tell. To be clear, VMPrint isn't meant to compete with established engines like that. It’s just a genuinely helpful tool I built from scratch for the specific tasks I needed to accomplish because I couldn't find an alternative. Prince looks powerful, but I have a feeling it probably wouldn't have been the right fit for my use case anyway. Prince starts at 2k. This is OSS Weasyprint [0] is OSS and supports CSS Paged media. I’m not actually sure why you’d ever use something like this project (or headless chrome for that matter, maybe you need some automated login as well?) which doesn’t. print-css.rock [1] has a good overview of available tools and their features. Because CSS is exactly what I wanted to avoid. I just needed predictable pager layout, and I didn't want to wrestle with CSS. Besides, this thing's tiny size allows it to run in a serverless function on the Edge, and that can be useful sometimes. So this is what it has come to? AI bots writing code and fake origin stories of said code and AI bots commenting on it any other bots responding? This is front page content now? HN: please require all AI generated content to be flagged as such. Ban offenders. This just blows. Unfortunately, your complex script shaping for Arabic and Devanagari is wrong. The Arabic is missing the joining (all forms are isolated), and the Devanagari doesn't have the vowels combining (so you see those dotted circles). To fix this you'll need Harfbuzz or something similar. Taking a quick look at the code, it seems like you're just doing a glyph at a time through the cmap. That, uh, won't do. You are completely right on all fronts. Thank you for taking a look at the code! You hit the exact architectural bottleneck. Right now, the engine uses Intl.Segmenter to find the grapheme boundaries, but then it just does a direct cmap lookup to get the advance widths. It currently lacks a parser for the OpenType GSUB (Glyph Substitution) and GPOS (Glyph Positioning) tables, which is why Arabic defaults to isolated forms and Indic matras don't fuse. The standard advice is exactly what you suggested: "just drop in HarfBuzz." But that creates an existential problem for this specific project. HarfBuzz is a massive C++ library. To run it in an Edge worker or pure V8 environment, I'd have to ship a WebAssembly binary that is often upwards of 1MB. That entirely defeats the purpose of building an 88 KiB, pure-JS, zero-dependency layout VM. Doing complex text layout (CTL) and shaping purely in JavaScript without exploding the bundle size is essentially the final boss of this project. The roadmap is to either implement a highly tree-shakeable, pure-JS parser for the most critical GSUB/GPOS rules, or find a way to pre-compile shaping instructions. For right now, it's a known trade-off: lightning-fast, edge-native pure JS layout, at the cost of failing on complex cursive ligatures. If you know of any micro-footprint pure-JS shaping libraries that don't rely on WASM, I am all ears! Not sure what's the point of it being so fast and so small if it's also wrong. what's the point of black and white statements that are wrong for a major subset of problems that the tool set out to solve? And what's the point of being right when it's slow and bloated? Come on, it works for a lot of use cases, and it doesn't work for some. And it's still evolving. As the person who implemented GSUB support for Arabic in Prince (via the Allsorts Rust crate), this post highly intrigued me… especially because I wanted to see how they implemented GSUB for Opentype while being a film director and possibly stunt double on the side. After seeing your comment, I’m saddened to see that OP and their comments in this threat are just bots. Looks interesting, but the "Why Not Just Use" section in the readme is definitely missing Typst. Would be interesting to know how they compare, since Typst is the obvious choice for typesetting nowadays, rather than LaTeX. Hi cosmiciron, wow, few humans find time to be a film director and a chief scientist and work on open-source projects. What about these strangely written strange sentences in the README? What does that mean? > In the 1980s and 90s, serious software thought seriously about pages. Or this?: > Desktop publishing software understood widows, orphans, and the subtle difference between a line break and a paragraph break. As the difference between a line break and a paragraph break is really subtle -could you elaborate a little bit? And that's precisely why I'm neither a blockbuster director nor a massively paid "chief scientist", LOL. As for the strange sentences? Before the web turned everything into paperless, infinite scrolls, people actually cared deeply about printed materials. With that came the strict requirement for pagination rules, widows, orphans, and deterministic behavior for margins. In fact, one of my favorite pieces of tech was built exactly around solving the discrepancy between display and print: NeXTSTEP with its Display PostScript technology. To answer your question about the subtle difference between a line and paragraph break: mathematically, they trigger completely different layout states in a typesetting engine. A line break (soft return) just wraps text to the next line while preserving the current block's alignment and justification math. A paragraph break (hard return) ends the semantic block entirely, triggering top/bottom margins, evaluating widow/orphan rules for the previous block, and resetting the layout cursor for the next. I had to build an engine that deeply understands this difference because in the film industry, screenplays are still written in Courier with strictly measured spatial margins and peculiar contextual rules on how blocks of dialogue break across pages. So this tool is basically my homage to an era long gone... Oh man -- I just wrote of these browserless markdown to pdf a few days ago.... Thanks for publishing [https://github.com/speajus/markdown-to-pdf.git](https://speajus.github.io/markdown-to-pdf). I didn't need anything this exacting. Anyways nice work; excited to look deeper. Every single screenshot of Arabic in the README is malformed, the letters are squished together and not connected. Good eye, you are right. A few others noticed this as well. It is a known trade off given the engine being pure JS and only 80K. The project is still at very early stage, and I'm definitely keeping my eyes open for solutions. Interesting! Generating PDFs with properly paginated content is still a pain point in 2026. Do you have a comprehensive integration test suite that can validate the robustness of your implementation? Exactly! That's someone speaking from experience, I can tell! :p And yes the tests are in there. And interestingly enough, because the engine emits its IR (in compressed JSON), I can use those as snapshots for the tests. They work better than relying on PDF or SVG outputs. >ai description >ai code >ai comments Why should we presume it’s an AI description? The writing seems reasonable enough. Some people are more naturally inclined towards articulate writing than others (seems like projection) and furthermore the OP claims to be a screenwriter. There is at least 1 em-dash per paragraph. /s I've read a lot of AI generated text and this is definitely one. However, I also believe in having an objective metric: https://files.catbox.moe/napzf6.png You are absolutely right about the AI content! This is not just a vibe-coded utility — this is a completely AI-driven conversation. /s I wonder what makes AI write its descriptions as puff pieces by default. devnagri in the screenshot is wrongly rendered. Also can you share some names of films you have been part of as film director. You are absolutely right about the Devanagari. That is a known trade-off at the moment. Because the core engine is strictly constrained to 88 KiB of pure JavaScript, it intentionally bypasses massive C++ shaping libraries like HarfBuzz. I haven't yet found a way to process complex text layout (CTL) and fuse those ligatures purely in JS without completely blowing up the bundle size. It's a very early implementation, but finding a micro-footprint solution for that is on the ROADMAP! Though, to be fair, for my original need—generating industry-standard screenplays from Markdown—the engine is already total overkill. LOL. As for the film: my feature premiered in January 2024 in China under the title 《天降大任》. It was originally developed in Los Angeles as an English-language project called Chosen. I actually put down my programmer's hat and worked on that film for over ten years! Are Unicode combining characters (dotted circles) visible on the screenshot by design? Incredible eye. You are absolutely right, and that is actually an artifact of the engine's current architecture! That screenshot includes the Hindi word 'देवनागरी' (Devanagari) and some Arabic text with diacritics. Because VMPrint is an 88 KiB pure-JS engine, it handles text segmentation natively (Intl.Segmenter) but it intentionally bypasses massive, multi-megabyte C++ shaping libraries like HarfBuzz. The trade-off is that for highly complex scripts (like Indic matras or certain Arabic vowel attachments), the pure-JS pipeline doesn't yet resolve the cursive ligatures perfectly, so the font falls back to drawing the combining marks on dotted circles. It mathematically calculates the bounding boxes correctly, but the visual glyph substitution isn't fused. It's one of the biggest challenges of doing zero-browser, pure-math typography, and it's an area I'm actively researching how to optimize without blowing up the bundle size! Curious but offtopic - are others also immediately suspicious of the content and quality because the readme is so obviously AI-written? What are ways you distinguish genuinely useful contributions on the sea of slop? Love it, love it! Thanks for sharing. Thank you for the kind words. I hope it becomes a useful part of your toolkit. It certainly is for my need to generate screenplays.
TimTheTinker - 2 hours ago
cosmiciron - 2 hours ago
irrationalfab - 2 hours ago
Semaphor - an hour ago
cosmiciron - 10 minutes ago
LastTrain - 2 hours ago
raphlinus - 4 hours ago
cosmiciron - 3 hours ago
Yiin - 2 hours ago
attila-lendvai - 42 minutes ago
cosmiciron - 2 hours ago
alfiedotwtf - 39 minutes ago
flexagoon - 4 hours ago
raphman - an hour ago
cosmiciron - 14 minutes ago
speajus - 4 hours ago
luaybs - 4 hours ago
cosmiciron - 2 hours ago
irrationalfab - 2 hours ago
cosmiciron - an hour ago
samlinnfer - 2 hours ago
colbyn - an hour ago
samlinnfer - an hour ago
orthoxerox - an hour ago
codegladiator - 4 hours ago
cosmiciron - 2 hours ago
koterpillar - 4 hours ago
cosmiciron - 3 hours ago
nodoodles - 2 hours ago
sriram_malhar - 2 hours ago
cosmiciron - 2 hours ago
{kind=link}